On September 27, I had the honor of doing a lightning talk in the Meetup Madrid C/C++, in IBM. Mine was the warm-up talk before Raúl Huertas, who was the main speaker with his fantastic talk about Sublime.
My talk was a small preview of a longer one that I want to propose for the next using std::cpp.
It can be downloaded here: Anticipo – Hagamos bibliotecas fáciles de usar
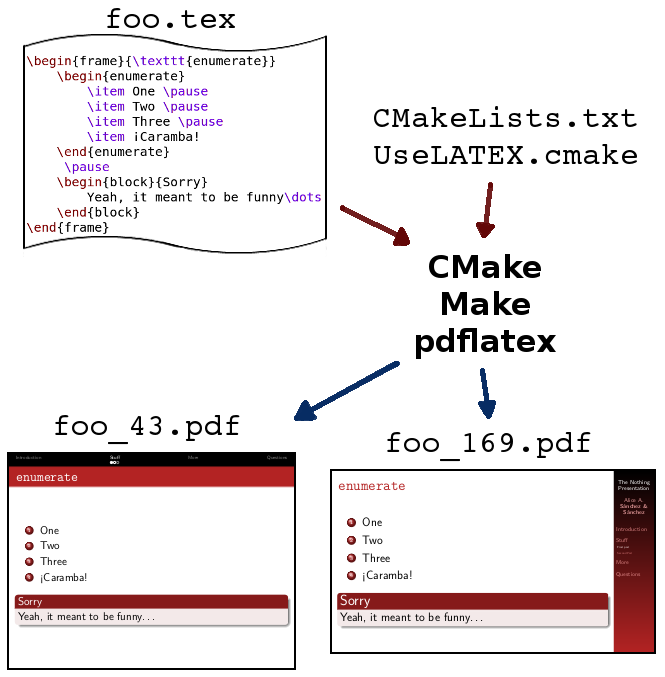
In a few words, this post explains a presentation template that I made. The special thing about it is that you can generate several PDFs of different aspect ratios from the same sources.
This is something I’ve been delaying for too long. Finally I found some time to sit down and write about this fascinating game, to which I dedicated so many hours. It often happens that the urgent things don’t leave time for the important ones. I’ll take a break and share this experience with you.
I started playing one or two games with my work colleagues at coffee time and I ended developing the Artificial Intelligence of the official App. Well, it’s a long story, so I’ll better start with the beginning.
It all started some years ago, when I taught programming in the University of Alcalá. One day a colleague brought a board game in a small cardboard box. Nowadays board games use to come in small boxes, but when I was a child the boxes were as impressive as the prices. Board games were designed to preside the largest piece of furniture in the living room, and for that purpose, first they had to preside the shop windows. Nobody thought that we would be obliged to get rid of the boxes while moving to a closet in the big city.
Whoops, I’m digressing. Martin, focus! The point is that the little game was a pleasant surprise. It turned out to be very funny and interesting.
Every tile has a number painted (and carved), along with one or more worms. The numbers range from 21 to 36. The first four tiles (from 21 to 24) have only one worm each. The next four (from 25 to 28) have two worms each, the next four (from 29 to 32) have three worms each, and the last four tiles (from 33 to 36) have four worms each.
The dice are normal except for the detail of having a worm in the side where normally would be the 6. In this game there are no sixes.
The goal of every player is to accumulate tiles. The more worms the better. At the end of the game each player’s worms are counted, and the player with more worms wins.
The game begins with all the tiles arranged in the center of the table. The players take turns to roll the dice and thus earn the tiles. In short I’ll explain how to roll the dice, which is another kettle of fish. The thing is that, with the points obtained in a turn, the player can grab from the center of the table the tile of that number or, if it’s not available, another tile of less value. But there’s more… Every player stacks the earned tiles by his side of the table. The tile on top of the stack is exposed to be stolen from another player who obtains with the dice the exact points of the tile.
It’s not easy to obtain the exact points to steal a tile from another player, but it’s worth to try. At the end of the day, the game is a race to get worms, and if we take them from the opponent, the advantage is double. The question is whether we’ll dare to steal from that dear relative or friend, who won’t precisely smile and give us a hug.
There’s one more little twist regarding the turn. If the dice roll doesn’t meet the criteria required to get a tile (neither from the center of the table nor from other player’s stack), the player looses the last tile obtained, which must be returned to the center of the table. In addition, every time a tile is returned to the center of the table, the most valuable tile in the center must be turned upside down. The tiles upside down are no longer part of the game.
A failed turn is doubly damaging: the player doesn’t get a new tile and besides that he looses one of the tiles earned previously.
The game ends when no tile remains face up on the center of the table.
The rule of turning upside down the most valuable tile helps avoiding the games to last forever. Dice rolls around 36 points are very unlikely, though perfectly possible. In the particular case where the returned tile is also the most valuable, the rule can be applied equally, or an exception can be made, leaving it face up. It’s convenient to reach an agreement regarding this point before starting the game.
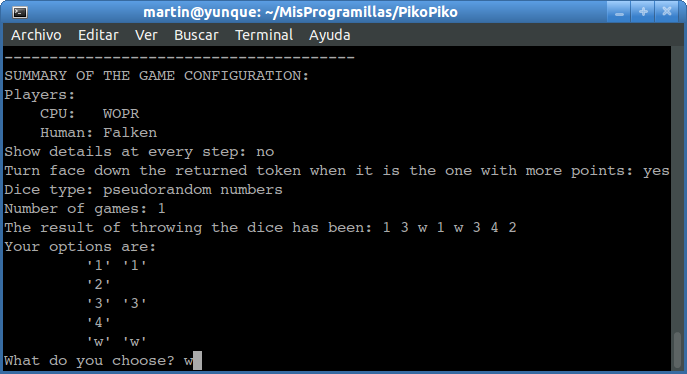
Well, now I’ll go for the dice subject. The faces from 1 to 5 are worth 1 to 5 points respectively. Quite normal. The side of the worm is worth 5 points, but it has an additional value that I’ll explain in short.
The player starts rolling the eight dice at once, but the points are not simply added. He has to choose the dice of one of the rolled values, and put them aside. The rest will have to be rolled again. For instance, let’s say that the roll has been { 1, 2, 2, 2, 2, 2, 4, 5 }. There are neither threes nor worms. We can choose to put aside:
1 = 1 point
2 + 2 + 2 + 2 + 2 = 10 points
4 = 4 points
5 = 5 points
But before choosing we must take into account how the rules affect the remaining dice:
We can roll the remaining dice, put aside the dice of another value to add points, and so on until… well, we’ll see until when.
We can’t put aside the dice of a value that we already put aside in this turn. That is, if we put aside a five and then we roll several fives more, we can’t use those fives. We’ll have to pick some other value… ¡if there’s any other value!
We can decide to settle and stop throwing dice when these two requirements are met:
that we have enough points to pick a tile from the center or from another player, and…
that we have put aside at least one worm (that’s what makes them so valuable!)
If every rolled value fatally coincides with something we already put aside, we loose our turn (and the tile earned more recently).
If no die remains to be rolled and we didn’t obtain any worm or we didn’t obtain enough points, we loose our turn (and the tile earned more recently).
In case there’s still any doubt, I insist: we can’t put aside just a 2 and roll the seven remaining dice. We must take either all the twos or the dice of some other value. We can’t roll the eight dice again. We must put something aside after every dice roll.
In light of these rules, the roll { 1, 2, 2, 2, 2, 2, 4, 5 } is dreadful. Let’s see our options one by one:
Put { 5 } aside and continue with 7 dice. In principle, this looks like the most attractive option: we get 5 points and go on with many dice. But watch out: after this we won’t be able to use any other 5 in this turn, and this limits the points we can expect to obtain with the remaining 7 dice.
Put { 4 } aside and continue with 7 dice. We get one less point. We won’t be able to put aside any more fours, but fives yes. This improves the average of points we can obtain with those seven dice.
Put { 2, 2, 2, 2, 2 } aside and continue with 3 dice. We get 10 points! But wait a minute…. We need 21 points at least and only three dice remain. In addition, we still need to roll some worm. In the best scenario we’d get a total of 25 points, which is no big deal, and chances are that we’ll loose this turn.
Put { 1 } aside and continue with 7 dice. We only get one point, but we preserve the right to use the fours and fives that we could roll with those 7 dice.
According to my calculations the best choice is to put the 4 aside. The probability of failure is under 4%.
The option of taking the 5 follows with a slightly lesser probability of failure, but also a lower benefit on average.
The option of taking the five twos is dreadful since it carries a failure probability around 38%.
Interestingly, the option of taking the 1 follows closely those of the 4 and 5. The probability of failure taking the 1 is greater, but still under 4%. The average benefit is only a bit lower.
The optimal algorithm for winning the game is not easy at all. Specifically, catching always the dice with higher values usually leads to very poor results. This kind of subtlety was what attracted me at first.
Since the very beginning I thought it would be interesting to compute the probabilities and make a program capable of playing Pickomino. I always found that programming the Artificial Intelligence of games is even more interesting than playing. In fact, I’ve dedicated many hours to some other game… I’ll talk about this another day.
The thing is that, at that point of my life, I couldn’t endeavour to do it just for fun. But a few years later, in 2012, I quit my job at the University to move abroad. For at least one year I’d have plenty of time to program whatever I pleased. In 2013, during one of my visits to Spain, I found the game in “Evolution Store”, Calle Manuel Silvela, 8, 28010 Madrid, Tel. 917582563. Free sponsoring, ladies and gentleman! Watch out: some other time I’ve gone to buy it again as a gift for a friend and they didn’t have it. It’s better to call first and ask to be sure.
Well I started programming and got something quite decent. The initial program chose which dice to put aside and whether it should settle or not, but it didn’t take into account which tiles were available. It only played trying to maximize the number of points obtained in a turn. It simulated around 50000 turns per second on my modest notebook (Atom @ 1.6 GHz), failing about one of every four turns and achieving an average of 26 points in the other three.
The final program beats me almost every time. I’ve won some time because luck is critical in this game, but the program uses to win with an advantage of a bunch of worms. But I’m getting ahead of the story… It took me some time to make the program play so well a full game.
How about a nice game of Piko Piko?
I did some research on Internet. To start, the game was named “Piko Piko, el gusanito” in Spain, but in other countries it’s called “Pickomino”, “Heckmeck am Bratwurmeck”, “Regenwormen”, “Kac-Kac Kukac”, “Il verme è tratto”, “Polowanie na Robale”…
I found out that the game was invented by Reiner Knizia. And I also found a video in which he mentioned, in a conference in 2011, that an App of the game would be developed, but apparently it was still unpublished.
I sent an email to offer my collaboration and in January 2014 he put me in contact with United Soft Media (USM), with whom he had reached an agreement to develop the application for mobile phones. Great!
A long series of emails followed until summer 2014. I developed a version of the program capable of playing full games, confronting players with different strategies. I perfected the strategies progressively to take into account the state of the game: which tiles are available on the center of the table, and which ones can be stolen, from whom is it more convenient to steal…
Finally, in April 2015, after a long wait, the App went on sale at the Apple Store and I can now brag about it to my friends. The illustrations follow the same line of the original board game, which I love, and the music and sound effects are very funny. How bad that they still didn’t make a version for Android! I had an iPhone long ago, but now I’m the happy user of a Samsung Galaxy. For the moment I have to resign myself and just play when I visit my parents and grab my mother’s phone.
The three revisions of the App you can see nowadays in the App store agree that the game is very funny. Though, one of them is quite negative: the user complains that the App crashes every time he selects “Lobby”. I don’t remember experiencing any crash, but the truth is I never got to play “online”. I ignore if this part of the App doesn’t work or if simply there was nobody connected when I tried. Maybe it depends on the country.
Another user complains that he can rarely win, and claims that the dice favour the AI. I do have a say on this subject. The AI wins more often because it plays very well. I ignore the details of how are the random numbers generated in the App, but I’m totally convinced that the dice are not loaded. It’s not necessary!
In fact, I would like the App to include a couple of specific functionalities:
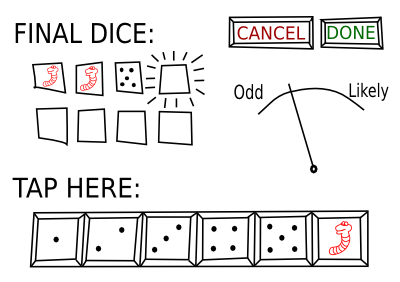
Allow the user to use real dice for both himself and the AI. It’s not even necessary to program an artificial vision module (though it would be very cool). A relatively simple screen would suffice. The user would tap the results after rolling the dice:
The “weirdnessmeter” would indicate how likely or unlikely is the tapped combination of values. For instance, rolling two dice there’s 1 chance out of 36 to get two worms, but there are 2 chances out of 36 to get a worm and a five, if we don’t care about the order (worm-five and five-worm).
Display the intentions of the AI player who is rolling the dice. For example, to mark lighting or darkening every tile depending on the confidence he has to obtain it, and surround the three most valued with yellow halos of different intensity.
Both functionalities would be optional. Naturally, their use would disable online game and the recording of achievements. The question is: would it be fun? I think it would! Not only to verify that the AI plays well with real dice, but also to learn from it and… to cheat on it some time!
Pickomino (“Piko Piko” in Spanish) is a small board game that I love. It’s a great gift, especially for families with children old enough to practice sums.
In addition I have the pride of having programmed the Artificial Intelligence of the official App, which you can find here.
In a previous entry I promised to talk about the cases where it makes sense to use your own implementation of a sorting algorithm. I will, but first I want to illustrate how badly twisted it can get.
When I say “fail horribly” I don’t mean the case of “not making it work” but the case of “making it work… until it happens to fail some day”. The latter is much worse.
Ignoring the fine print is a mistake. Grabbing a book on algorithms and implementing your own version of algorithm X without reading the full chapter can be a huge mistake.
Let’s review, as a practical case, the mistakes commonly made while implementing quicksort:
To leave the pivot inside one of the parts (possible infinite recursion).
To use always the first element as pivot (or always the last).
To believe that using as pivot the median of 3 or a random element avoids completely the worst case.
To make two recursive calls instead of using tail recursion.
To use tail recursion, but always on the same side.
To believe that using tail recursion solves all problems. It reduces the memory required in the worst case, but not the time.
To leave all elements equal to the pivot on one side. If you do this, quicksort will show its worst behaviour also in the case where all elements (or many) are equal.
I’ll explain the previous issues one by one:
1. To leave the pivot inside one of the parts
While partitioning, it’s good to leave the pivot in its final place, and not inside one of the parts to be sorted. This might look like a small, unimportant optimization, but it isn’t.
If we leave the pivot inside one of the parts to be sorted, and this part fatally happens to be the whole array to be sorted (being the other part empty), then we provoke an infinite recursion.
Several details determine the impact of this issue, like the choice of the pivot or whether the elements equal to the pivot are distributed or left on one side. Though, the only way to completely solve this problem is to exclude the pivot from both parts, leaving it placed in its final position. This way we guarantee that every recursive call reduces the problem size by at least one element.
2. To use always the first element as pivot (or always the last)
This would be less important if all possible permutations happened with the same probability. But reality is different. The special cases of “already sorted data” (either in straight order or reverse) or “almost sorted data” are quite frequent in comparison with other permutations. And in these cases, the first and last elements are the worst candidates we can choose as pivot.
If we use always the first element (or always the last) as pivot, quicksort degenerates into its worst behaviour with already sorted data, no matter whether they are in ascending or descending order.
This problem is usually attacked in two different ways:
To use as pivot the median of three elements: the fist, the last and the middle one
To use as pivot the element of a position chosen at random
Both methods reduce the probability of the worst case, but they can’t eliminate it completely.
3. To believe that using as pivot the median of 3 or a random element avoids completely the worst case
The worst case can still happen. It might be very unlikely, but it’s still possible. This is the kind of problem that goes through testing undetected and shows up later, when the consequences are serious.
It’s not only a question of probability. An attacker might feed our system with data arranged exactly in the way that provokes quicksort’s worst behaviour.
We must take into account that the worst case can happen. It’s quite convenient that tests exercise it in order to evaluate the consequences regarding the required time and additional memory.
4. To make two recursive calls instead of using tail recursion
Tail recursion is implemented replacing one of the recursive calls with a loop. This way we slightly reduce the execution time.
It looks like a simple optimization, but in reality this is necessary to reduce the additional memory to O(log N), even in the worst case. Though, it is not enough to simply use tail recursion in any way. I’ll explain why.
5. To use tail recursion, but always on the same side
If tail recursion is not used, or if it is used always on the same side, the required additional space in the worst case will be in the order of O(N), that is, proportional to the number of elements to be sorted. This can provoke a stack overflow.
The reason is that, in the worst case, up to O(N) recursive calls will be nested, and every one of them takes some memory.
The only way to solve this is to use tail recursion in the recursive call that corresponds to the largest part. This way we ensure that only O(log N) recursive calls will be nested.
6. To believe that using tail recursion solves all problems
Tail recursion, used correctly, solves the space problem. But there are still other problems. The time of the worst case is still
O(N2)
. As I’ve already pointed out, the choice of the pivot can help in making this case very unlikely in practice. If “very unlikely” is not enough, then we must resort to some other algorithm that takes O(N log N) time also in the worst case, even though the average case takes several times quicksort’s average time.
But this is not the end. There’s still a subtle detail that can turn this “very unlikely” in “embarrassingly common”:
7. To leave all elements equal to the pivot on one side
While partitioning, what should we do with the elements that happen to be equal to the pivot? At first sight this looks like an unimportant detail. We can leave them in any of the two sides. The algorithm will sort properly. In addition, there won’t be too many elements equal to the pivot, will they? Oh! Wait a moment… Maybe there are lots of them!
When we talk about sorting algorithms we tend to think of arrays full of different values. But in real life if happens quite often that many elements have the same value. Suppose that we need to sort the data of 47 million citizens according to their marital status (single, married…). After a couple of recursion levels, chances are that all, or almost all the elements of the fragment to be sorted are equal regarding marital status. What will happen then.
The probability of choosing a pivot with that repeated value is very high. Therefore, many elements will be equal to the pivot. If we put them all at the same side we will have an inefficient partition. The worst partition indeed! Quicksort will exhibit its worst behaviour in a case that, in principle, seemed absurdly easy. This is most certainly the biggest problem because algorithms textbooks don’t emphasize it enough, if they ever mention it.
The solution is to distribute the elements equal to the pivot among both parts, even though it might seem at first sight that we are moving data around unnecessarily. You can find an implementation here.
However, I insist: the best option is almost always to use the sorting method provided by the programming language in its functions library ;-)
In C++, for instance, you can choose between std::sort and std::stable_sort.
In the field of sorting with little additional memory there have been several favorites along the history: ShellSort (1959), quicksort (1960), heapsort (1964) and more recently introsort (1997), which is a hybrid of quicksort, heapsort and insertion sort.
Mergesort (1945) dominated many years in the field of stable sorting. Its replacement seems to be Timsort (2002). It is also a hybrid, this time of mergesort, insertion sort and a few more tricks.
I will discuss the few cases where it makes sense (in my opinion) to tailor your own implementation of a sorting algorithm. But I’ll do it later ;-)
ProjectEuler.net is a great invention that I discovered a couple of years ago. It houses a very interesting collection of programming problems.
The first ones are relatively simple. Then the difficulty increases as you advance through the list of problems.
Every problem is designed to be solved with less than one minute of processing in a normal computer. Many take just a few microseconds. Any language like C or Java with 64 bit integers should suffice. Many people use other languages.
In principle, new users only have access to the problem statements.
For every problem there is a forum where previous users have been sharing their solutions. For many problems there is also a PDF overview explaining possible solutions.
But users can only access the forum and the PDF overview of a problem after solving it and entering the correct answer on the website.
At first glance this might seem a nonsense. What’s the point if the user has already found the solution? There’s a big point, indeed! There are often several ways to solve a problem and they are not all equally efficient. The forum and the PDF overview contain vital clues to approach future problems.
Out of the hundreds of problems that exist in Project Euler, I have solved 81 to date. As a result I have learned a lot about combinatorics and dynamic programming, among other things. About the latter, by the way, I plan to write some day on this blog.
Aside from having solved a few problems, I can proudly say that I contributed my bit to Project Euler: I volunteered for the preparation of the PDF overviews for problems 31 and 53.
Unfortunately, Project Euler has been a while running at half speed. Administrators discovered that someone had sneaked into their database and they shut down the website. They reopened it later but with “reduced functionality”. That is, you can access the problem statements and you can check whether a solution is correct, but there are no forums or PDF overviews.
Reproducing here the problem statements or giving clues to the solutions would go against the philosophy of Project Euler, so I will just link the statements …
“Of course! I do it every day” – you must be thinking.
No, no, no. I assume you can tie your shoelaces. What I wonder is if you know how do you do it. Could you describe it step by step, in words or pictures? That’s another kettle of fish… You are not allowed to test it. You can not even look at your shoes. How do you move each finger at every step?
If you can describe how to tie shoelaces, it’s probably because you had to teach someone how to do it.
Something similar happens with programming. We have to teach the computer how to perform tasks that we can do. But we have to describe them in detail, in a very limited language. Nothing is understood implicitly by the computer. We often find ourselves thinking hard to separate the elementary steps of a process that we perform automatically, almost unconsciously.
Therein lies one of the difficulties of programming. The other difficulty is that, expanding the analogy, we need the computer to do all known sailor knots… and some more.
Blog about programming and whatever I come up with