ACTUALIZACIÓN (21/03/2019): Desde hace unos días mantengo una versión muy cambiada y mejorada de esta idea en mi proyecto CppLibraryInterfacePoC en GitHub:
Ayer 27 de septiembre tuve el honor de dar una charla relámpago en el Meetup Madrid C/C++, en IBM. Hice de telonero para Raúl Huertas, que fue el ponente principal con su fantástica charla sobre Sublime.
Mi presentación fue un pequeño anticipo de otra más larga que quiero proponer para el próximo using std::cpp.
Se puede descargar aquí: Anticipo – Hagamos bibliotecas fáciles de usar
Últimamente he asistido a varias presentaciones (a una de ellas, como ponente). Es trágico que en pleno año 2016 sigamos sufriendo el problema del formato.
Pensándolo bien, es triste pero completamente normal. Los cañones proyectores son caros, y algunos además duraderos. ¿Vamos a tirar a la basura un cañón porque sea de formato 4:3? De hecho, si tenemos una pared 4:3 y presupuesto para cubrirla entera, ¿tiene sentido que compremos un cañón 16:9?
El caso es que seguimos viendo presentaciones que desaprovechan el valioso (¡y costoso!) espacio disponible sencillamente porque están pensadas para el formato incorrecto.
En el mejor de los casos vemos una presentación 4:3 con bandas negras a los lados, en una gran pantalla 16:9. Otras veces es al revés: una presentación 16:9 con bandas arriba y abajo, en una vieja pantalla 4:3. Este caso es peor, porque las pantallas 4:3 suelen ser más pequeñas, ya sea por limitaciones tecnológicas (son más antiguas), presupuestarias o… ¡por la altura de la pared!
Hay un remedio que resulta ser peor que la enfermedad: estrujar la presentación para adaptarla al formato de la pantalla. ¡Pobres letras! Casi las oigo chillar aplastadas. Y finalmente, el colmo del colmo: letras estrujadas y barras al mismo tiempo. Yo he sido testigo. Quizás esto ocurre cuando se hacen presentaciones consecutivas con diferentes formatos y nadie se para a configurar las cosas.
¿Se puede culpar al ponente?
El ponente no suele saber con antelación si la pantalla será 4:3 ó 16:9. Es frecuente que en un mismo evento haya pantallas de ambos formatos, y siempre suele haber cambios de última hora.
Hace un par de meses yo mismo di una charla (sobre el manejo de estructuras de datos en C++) y la pantalla era de formato 4:3, pero después se iba a montar un vídeo de la charla en formato 16:9.
Entonces, ¿qué se puede hacer? ¿Preparar la presentación en los dos formatos?
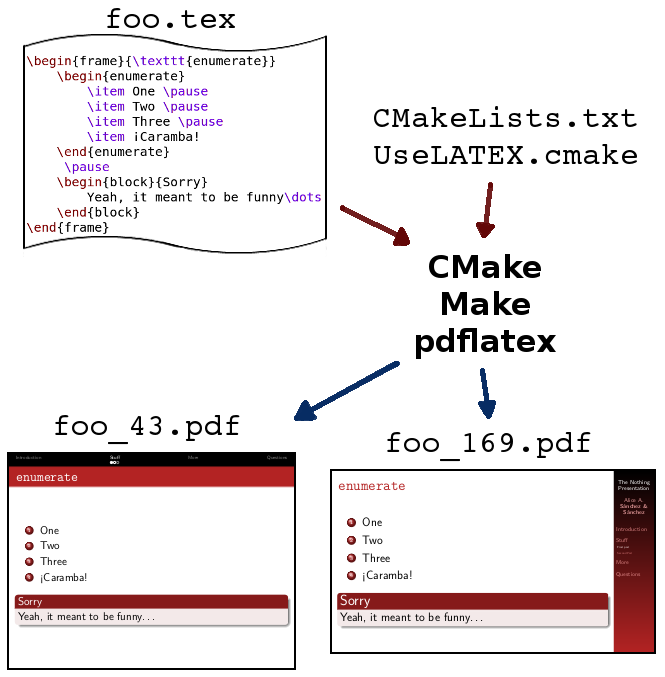
Pues sí. Exactamente. Y ahí los que usamos LaTeX y beamer estamos de enhorabuena, porque CMake con UseLATEX.cmake puede hacer el trabajo sucio por nosotros.
Beamer ofrece una gama de temas predefinidos para las presentaciones. Por un lado se puede elegir la gama de colores. Por otro lado se puede elegir la distribución de ciertos elementos, como el título de la transparencia, la sección a la que pertenece, el número de transparencia etc. Algunos temas muestran más detalles de este tipo que otros.
Lo interesante en el caso que nos ocupa es que unos temas utilizan barras horizontales para estos elementos mientras que otros temas utilizan barras verticales.
Si utilizamos un tema con barras horizontales para 4:3 y otro con barras verticales para 16:9, el espacio que queda para el contenido real de las transparencias es aproximadamente de la misma proporción en ambos formatos.
Esto es exactamente lo que hice para mi presentación de hace unos meses:
Escribí el contenido en sí una sola vez.
Seleccioné un tema apropiado para 4:3 (Frankfurt) y generé el PDF ejecutando pdflatex
Cambié el formato y el tema para 16:9 (Marburg) y generé otro PDF ejecutando pdflatex de nuevo
Cambiando además el tamaño de las fuentes (14pt en 4:3 y 17pt en 16:9), los contenidos de las transparencias encajaron casi igual en las dos versiones, aprovechando al máximo el espacio disponible sin sacrificar la legibilidad.
También puede ser interesante generar la versión «handout» (*) para entregarla a los asistentes en papel o para colgarla en internet, así que ya son al menos tres PDFs. Cuatro, si queremos el «handout» en ambos formatos.
* handout: En muchas presentaciones se usa el truco de ir mostrando los contenidos de una misma transparencia progresivamente. Con beamer este efecto se consigue generando varias páginas sucesivas para una sola transparencia. En el «handout» aparece sólo la página final (con todo a la vista) de cada transparencia. Además, con beamer es posible configurar transparencias individuales para que aparezcan en la presentación, pero no en el «handout», o al revés.
UseLATEX.cmake es ideal para automatizar todo esto.
Hace unas semanas decidí poner un poco de orden de cara a la próxima presentación. Ya hice algún Makefile para mis documentos en Latex hace años, pero me apetecía probar algo más moderno. Tras una búsqueda rápida me decanté por UseLATEX.cmake y probé a montar una plantilla: https://github.com/mkrevuelta/TheNothingPresentation
Como en cualquier proyecto compilado con ayuda de CMake, el orquestador principal es el archivo CMakeLists.txt. En él se utilizan funciones de UseLATEX.cmake para definir los cuatro objetivos (los PDF en distintos formatos) indicando de qué archivos dependen.
Por cada uno de los cuatro objetivos hay un archivo TEX que contiene la línea inicial del documento Latex:
Presentation_43.tex
Presentation_43_handout.tex
Presentation_169.tex
Presentation_169_handout.tex
El primero de ellos, por ejemplo, contiene:
% Dear text editor,
% Please, keep this file encoded in in latin1 (ISO-8859-1).
% Here are some Spanish special characters: áéíóúüñÁÉÍÓÚÜÑ
\documentclass[14pt]{beamer}
% Available font sizes are:
% 8pt, 9pt, 10pt, 11pt, 12pt, 14pt, 17pt, 20pt
\input{src/latex/Colors.tex}
\input{src/latex/Header_43.tex}
\input{src/latex/Presentation.tex}
El segundo es igual, pero con el parámetro adicional handout en la línea del documentclass. Los dos últimos añaden el parámetro aspectratio=169 e incluyen al archivo Header_169.tex en vez de Header_43.tex.
Aparte de esas diferencias, los cuatro objetivos usan el mismo código. Todos incluyen a Colors.tex y Presentation.tex.
El contenido propiamente dicho de la presentación es sólo un pequeño catálogo de los trucos más sencillos que suelen utilizarse en beamer. Está repartido en varios archivos TEX simplemente por organización y limpieza.
Todo el contenido está en el directorio src. El subdirectorio src/latex contiene los archivos en texto plano (con codificación latin1). El subdirectorio src/figs contiene las imágenes.
Por la forma en que funciona UseLATEX.cmake, es necesario que todas las referencias de unos TEX a otros, o a las figuras, se hagan como si el directorio actual fuera el de CMakeLists.txt. Por ejemplo, en Presentation.tex hay que incluir a 1_Intro.tex especificando \input{src/latex/1_Intro.tex}, aunque ambos se encuentren en el directorio src/latex.
Quizás lo más conveniente, al menos la primera vez, es poner a prueba todo el sistema generando los PDF a partir de los fuentes tal y como están. Naturalmente es necesario tener instalados CMake y Latex con beamer. También hay que descargar UseLATEX.cmake (disponible en https://cmake.org/Wiki/CMakeUserUseLATEX y en https://github.com/kmorel/UseLATEX) y copiarlo en la misma carpeta del CMakeLists.txt.
Entonces, desde esa carpeta hay que ejecutar «cmake .«, y finalmente «make«. Con la primera orden se despliega un directorio build junto a src y con la segunda se generan los cuatro PDF objetivo dentro de ese directorio.
El siguiente paso es, quizás, adaptar el «look» de la presentación: tema externo, colores, tamaño de letra etc.
Ya sólo queda cambiar los datos del autor y otros detalles de la portada en TitlePageData.tex, y comenzar a escribir el contenido de la nueva presentación.
Naturalmente, querrás organizar tu presentación en otras secciones diferentes y querrás usar otras imágenes. Para ello debes tener en cuenta que los archivos TEX incluyen directamente a otros archivos TEX e imágenes, pero además es imprescindible que el archivo CMakeLists.txt informe a CMake de la dependencia de esos archivos. De lo contrario CMake no los copiará al directorio build y después pdflatex no los encontrará.
Cada vez que añadas, elimines o cambies el nombre de una imagen o un archivo TEX, debes actualizar CMakeLists.txt y ejecutar de nuevo «cmake .«.
Nota sobre las imágenes
Las conversiones de imágenes para Latex tienen sus trucos. Yo solía utilizar unos cuantos programas de conversión, pero creo que en lo sucesivo intentaré generarlas siempre en formato PNG ó EPS, que parecen funcionar bien con UseLATEX.cmake.
Cabe destacar que la imagen someicon.svg, pese a estar en un formato vectorial, ha sido convertida a mapa de bits al generar la presentación. Idealmente no debería ser así, pero si ampliamos la transparencia en la que aparece veremos unos píxeles como puños.
Hace bastantes años que, al menos en casa, soy un feliz usuario de Ubuntu. No estoy seguro de cuál es la lista completa de paquetes necesarios, pero sin duda hará falta tener latex-beamer y cmake.
También hay que descargar UseLATEX.cmake, disponible en:
Hasta donde yo sé, todo esto debería funcionar también en otros sistemas operativos. Yo no lo he probado, pero me encantaría saber de vuestras experiencias, así que si lo probáis, escribidme unas líneas ;-)
Hace tiempo que tengo pendiente escribir sobre este juego que me fascina y al que he dedicado muchas horas. A menudo nos ocurre que lo urgente no deja tiempo para lo importante, así que voy a tomarme un rato para compartir esta experiencia con vosotros.
Empecé echando una partida o dos con los compañeros de trabajo a la hora del café y acabé desarrollando la Inteligencia Artificial de la App oficial. En fin, es una historia larga, así que empezaré por el principio.
Todo empezó hace ya unos cuantos años, cuando enseñaba programación en la Universidad de Alcalá. Un día un compañero trajo un juego de mesa en una pequeña caja de cartón. Hoy en día es normal que los juegos de mesa vengan en cajas pequeñas, pero cuando yo era pequeño las cajas eran tan impactantes como el precio. Los juegos de mesa estaban diseñados para presidir el mueble del salón, para lo cual, antes tenían que presidir el escaparate de la tienda. Nadie pensó que acabaríamos viéndonos obligados a deshacernos de las cajas al mudarnos a una solución habitacional.
Vaya, estoy desbarrando. ¡Martín, céntrate! El caso es que el jueguecito me sorprendió gratamente. Resultó ser muy interesante y muy divertido.
Cada ficha tiene dibujados (y en relieve) un número y uno o más gusanos. Los números van del 21 al 36. Las primeras cuatro fichas (del 21 al 24) tienen sólo un gusano cada una. Las siguientes cuatro (del 25 al 28) tienen dos cada una, las siguientes cuatro (del 29 al 32) tienen tres cada una, y las últimas cuatro fichas (del 33 al 36) tienen cuatro gusanos cada una.
Los dados son normales salvo por el detalle de tener un dibujo de un gusano en la cara donde normalmente estaría el 6. En este juego no hay seises.
El objetivo de cada jugador es acumular fichas. Cuantos más gusanos, mejor. Al terminar la partida se cuentan los gusanos de las fichas de cada jugador, y gana el que más gusanos tenga.
Al comienzo de la partida todas las fichas se colocan en el centro de la mesa. Los jugadores se turnan para tirar los dados y ganar así las fichas. Enseguida explicaré cómo se tiran los dados, que tiene su miga. El caso es que, con los puntos obtenidos en un turno, el jugador puede coger del centro de la mesa la ficha de ese número o, si esa no está disponible, una de menos puntos. Pero hay más… Cada jugador va apilando las fichas ganadas en su lado de la mesa. La ficha que se encuentra a la vista, es decir, en la cima de la pila, está expuesta a ser robada por otro jugador que obtenga con los dados la puntuación exacta de la ficha.
No es fácil conseguir los puntos exactos para robar una ficha a otro jugador, pero merece la pena intentarlo. Al fin y al cabo, el juego es una carrera por obtener gusanos, y si se los quitamos al oponente, la ventaja es doble. La cuestión es si nos atreveremos a robarle la ficha a ese querido familiar o amigo, que además no se va a quedar cruzado de brazos…
Queda otro detalle respecto al turno. Si la tirada no cumple los requisitos necesarios para obtener una ficha (ni del centro de la mesa ni de la pila de otro jugador), el jugador pierde la última ficha que obtuvo, que vuelve al centro de la mesa. Además, cada vez que se devuelve una ficha al centro de la mesa, se coloca boca abajo la ficha del centro de la mesa con mayor puntuación. Las fichas que quedan boca abajo ya no forman parte del juego.
Un turno fallido es doblemente perjudicial: el jugador no consigue una nueva ficha y encima pierde una ficha de las que ya había ganado.
El juego termina cuando ya no queda ninguna ficha boca arriba en el centro de la mesa.
La norma de colocar boca abajo las fichas de mayor puntuación sirve para impedir que las partidas se eternicen. Las tiradas de alrededor de 36 puntos son muy improbables, aunque perfectamente posibles. En caso de que la misma ficha devuelta sea la de más puntuación, se puede aplicar la norma tal cuál o se puede hacer una excepción y dejarla boca arriba. Antes de comenzar el juego, conviene acordar qué se va a hacer en estos casos.
Bien, ahora voy a tratar el tema de los dados. Las caras del 1 al 5 valen de 1 a 5 puntos respectivamente. Normal. La cara del gusano vale 5 puntos, pero tiene otro valor añadido que explicaré en breve.
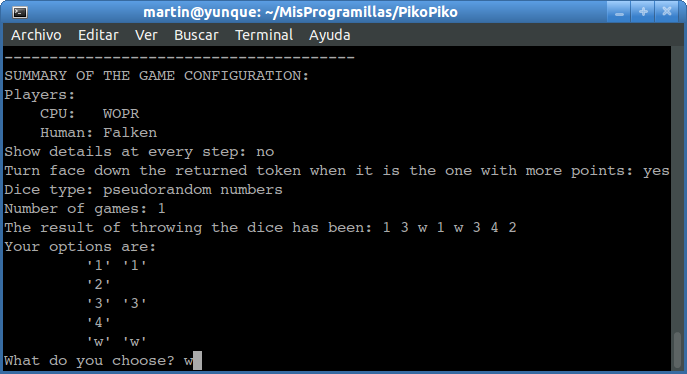
Se empieza lanzando los ocho dados a la vez, pero los puntos no se suman sin más. Hay que escoger los dados de uno de los valores que han salido, y apartarlos. El resto habrá que lanzarlos de nuevo. Por ejemplo, supongamos que ha salido { 1, 2, 2, 2, 2, 2, 4, 5 }. No han salido treses ni gusanos. Podemos optar por apartar:
1 = 1 punto
2 + 2 + 2 + 2 + 2 = 10 puntos
4 = 4 puntos
5 = 5 puntos
Pero antes de elegir, debemos tener en cuenta las normas que afectan a los demás dados:
Podremos volver a tirar los dados restantes, apartar los de otro valor para ir sumando puntos, y así sucesivamente hasta… bueno, ahora veremos hasta cuándo.
No podremos volver a apartar los dados de un valor que ya hayamos apartado en este turno. Es decir, que si apartamos el cinco y después salen más cincos, ya no podremos aprovechar esos cincos. Tendremos que apartar algún otro valor… ¡si sale!
Podemos plantarnos y dejar de lanzar los dados cuando se cumplan estos dos requisitos:
que tengamos suficientes puntos para robar una ficha del centro de la mesa o de otro jugador, y…
que hayamos conseguido apartar al menos un gusano (¡por eso son tan valiosos!)
Si todos los valores que salen en una tirada coinciden con valores que ya hemos apartado, perdemos el turno (y la última ficha ganada).
Si agotamos los dados sin haber conseguido gusanos o sin haber sumado suficientes puntos, perdemos el turno (y la última ficha ganada).
Por si cabe alguna duda, insisto: no podemos apartar sólo un 2 y volver a tirar los siete dados restantes. O cogemos todos los doses, o cogemos los de otro valor. Tampoco podemos volver a tirar todos los dados. Tenemos que apartar algo cada vez.
A la vista de estas reglas, la tirada { 1, 2, 2, 2, 2, 2, 4, 5 } es francamente mala. Veamos las opciones una por una:
Apartar { 5 } y seguir con 7 dados. En principio parece la opción más atractiva: conseguimos 5 puntos y seguimos con muchos dados. Pero cuidado: ya no podremos usar ningún 5 en este turno, y eso limita los puntos que podemos obtener con los 7 dados restantes.
Apartar { 4 } y seguir con 7 dados. Conseguimos un punto menos. No podremos apartar más cuatros, pero sí cincos. Eso aumenta la media de puntos que podríamos obtener con esos siete dados.
Apartar { 2, 2, 2, 2, 2 } y seguir con 3 dados. ¡Conseguimos 10 puntos! Pero un momento… Necesitamos al menos 21 puntos y nos quedan sólo tres dados. Además aún tenemos que sacar algún gusano. En el mejor de los casos obtendríamos un total 25 puntos, que no es gran cosa, y lo más probable es que perdamos el turno.
Apartar { 1 } y seguir con 7 dados. Sólo conseguimos un punto, pero conservamos la posibilidad de coger los cuatros y los cincos que puedan salir con esos 7 dados.
Según mis cálculos la mejor opción es coger el 4. La probabilidad de fallo es inferior al 4%.
Le sigue la opción de coger el 5, con una probabilidad de fallo levemente inferior, pero con un beneficio medio también inferior.
La opción de coger los cinco doses es pésima porque conlleva una probabilidad de fallo de alrededor del 38%.
Curiosamente, la opción de coger el 1 sigue de cerca a las del 4 y el 5. La probabilidad de fallo cogiendo el 1 es levemente superior, pero sigue estando por debajo del 4%. El beneficio medio es sólo ligeramente inferior.
El algoritmo óptimo para ganar el juego no es nada sencillo. Concretamente, coger siempre los dados con valores más altos suele dar muy malos resultados. Este tipo de sutilezas fue lo que me atrajo en un primer momento.
Desde el principio pensé que sería interesante calcular las probabilidades y hacer un programa que pudiera jugar al Piko Piko. Siempre me ha parecido que programar la Inteligencia Artificial de un juego es incluso más interesante que jugar. De hecho, he dedicado bastantes horas a algún otro juego… hablaré de ello otro día.
El caso es que en aquel momento no tenía tiempo para embarcarme en algo así por placer. Pero unos cuantos años más tarde, en 2012, dejé mi trabajo en la universidad para irme a vivir al extranjero. Por al menos un año tendría tiempo de sobra para programar lo que me apeteciera. En 2013, en una de mis visitas a España encontré el juego en «Evolution Store», Calle Manuel Silvela, 8, 28010 Madrid, Tfno. 917582563. ¡Propaganda gratuita, oigan! Ojo, porque alguna vez he ido con la intención de comprarlo de nuevo para regalárselo a algún amigo y no tenían. Conviene llamar antes y asegurarse.
En fin, que me puse a programar y conseguí algo bastante decente. El programa inicial elegía qué dados apartar y si debía plantarse o no, pero no tenía en cuenta qué fichas estaban disponibles. Sólo jugaba buscando maximizar el número de puntos en un turno. Simulaba unos 50000 turnos por segundo en mi modesto notebook (Atom @ 1.6 GHz), fallando una cuarta parte de los turnos y consiguiendo una media de 26 puntos en las otras tres cuartas partes.
El programa final me gana casi siempre. Alguna vez le he ganado yo porque la suerte juega un papel decisivo en este juego, pero lo normal es que me gane con unos cuantos gusanos de ventaja. Pero ya me estoy adelantando… Pasó algún tiempo antes de que mi programa llegase a jugar tan bien una partida completa.
How about a nice game of Piko Piko?
Investigué un poco en internet. Para empezar, el juego se llama «Piko Piko, el gusanito» en España, pero en otros países se llama «Pickomino», «Heckmeck am Bratwurmeck», «Regenwormen», «Kac-Kac Kukac», «Il verme è tratto», «Polowanie na Robale»…
Averigüé que el inventor del juego es Reiner Knizia. Encontré un vídeo en el que comentaba, en una conferencia de 2011, que iban a desarrollar una App del juego, pero parecía que aún no estaba publicada.
Le envié un email para ofrecerle mi colaboración y en enero de 2014 me puso en contacto con United Soft Media (USM), con quienes había llegado a un acuerdo para desarrollar la aplicación para móviles. ¡Genial!
Siguió una larga serie de correos hasta el verano de 2014. Desarrollé una versión del programa que pudiera jugar partidas completas, enfrentando jugadores con diferentes estrategias. Fui perfeccionando las estrategias para tener en cuenta el estado del juego: qué fichas están disponibles en el centro de la mesa, y cuáles se pueden robar, a qué contrincante conviene más robar…
Finalmente, en Abril de 2015, tras una larga espera, la App salió a la venta en la tienda de Apple y ya puedo presumir ante mis amigos. Los dibujos siguen la línea del juego de mesa original, que me encanta, y la música y los efectos de sonido son muy divertidos. ¡Qué rabia que aún no hayan hecho una versión para Android! Tuve un iPhone hace tiempo, pero ahora soy el feliz usuario de un Samsung Galaxy. De momento tengo que conformarme con jugar cuando visito a mis padres y engancho el teléfono de mi madre.
Las tres revisiones de la App que se pueden ver a día de hoy en la App store coinciden en señalar que el juego es muy divertido. No obstante, una de ellas es muy negativa: el usuario se queja de que la aplicación se cuelga cada vez que selecciona «Lobby». Yo no recuerdo que se me haya colgado, pero la verdad es que nunca he conseguido jugar «online». No sé si esa parte de la aplicación no funciona o si simplemente no había nadie conectado cuando yo lo intenté. Quizá depende del país.
Otro usuario se queja de que rara vez consigue ganar y dice que los dados favorecen a la IA. Ahí sí que tengo algo que decir. La IA gana más a menudo porque juega muy bien. Desconozco los detalles de cómo se están generando los números aleatorios en la App, pero estoy totalmente convencido de que los dados no están trucados. ¡No es necesario!
De hecho, a mí me gustaría que la App incluyera un par de funcionalidades específicas:
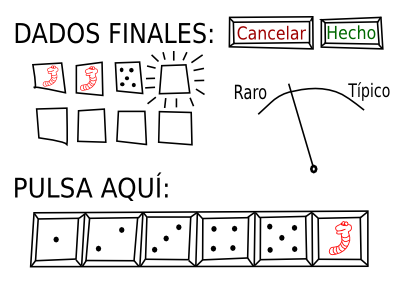
Permitir al usuario utilizar dados reales, tanto para sí mismo como para la IA. Ni siquiera hace falta programar un módulo de visión artificial (aunque sería chulísimo). Basta con una pantalla relativamente sencilla para que el usuario marque los resultados tras tirar los dados:
El «rarímetro» indicaría lo rara o probable que es la combinación de valores introducida. Por ejemplo, tirando dos dados hay 1 posibilidad entre 36 de sacar dos gusanos, pero hay 2 posibilidades entre 36 de sacar un gusano y un cinco si no nos importa el orden (gusano-cinco y cinco-gusano).
Mostrar las intenciones del jugador que está tirando los dados. Por ejemplo, marcar iluminando u oscureciendo cada ficha en función de la esperanza que tiene de obtenerla, y rodear las tres mejor valoradas con halos amarillos de diferente intensidad.
Ambas funcionalidades serían opcionales. Naturalmente, su uso deshabilitaría el juego online y el registro de logros. La cuestión es: ¿sería divertido? ¡Yo creo que sí! No sólo para comprobar que la IA juega bien con dados reales, sino para aprender de ella y… ¡para hacerle alguna trampeja!
Piko Piko («Pickomino» en inglés) es un pequeño juego de mesa que me encanta. Es un regalo magnífico, sobre todo para familias con niños en edad de practicar las sumas.
Además tengo el orgullo de haber programado la Inteligencia Artificial de la App oficial, que podéis encontrar aquí.
En una entrada anterior prometí hablar de los casos en los que tiene sentido usar tu propia implementación de un algoritmo de ordenación. Hablaré de ello, pero antes quiero hacer un inciso para ilustrar hasta qué punto se pueden torcer las cosas.
Cuando digo «fallar horriblemente» no me refiero al caso de «no conseguir que funcione» sino al caso de «conseguir que funcione… hasta que un día falla». Esto último es mucho peor.
Ignorar la letra pequeña es un error. Coger un libro sobre algoritmos e implementar tu propia versión del algoritmo X sin leer el capítulo completo puede ser una metedura de pata tremenda.
Veamos, como caso práctico, los errores comunes al implementar quicksort:
Dejar el pivote dentro de una de las partes (posible recursividad infinita).
Usar siempre el primer elemento como pivote (o siempre el último).
Creer que usar como pivote la mediana de 3 o un elemento al azar evita completamente el peor caso.
Hacer dos llamadas recursivas en vez de utilizar recursividad de cola.
Utilizar recursividad de cola, pero siempre en el mismo lado.
Creer que la recursividad de cola evita todos los problemas. Reduce la memoria requerida en el peor caso, pero no el tiempo.
Dejar todos los elementos iguales al pivote en un lado. Si se hace esto, quicksort mostrará su peor comportamiento también en el caso de que todos (o muchos) valores sean iguales.
Explicaré uno a uno los puntos anteriores:
1. Dejar el pivote dentro de una de las partes
Al hacer la partición conviene que el elemento elegido como pivote quede ya en su sitio, y no dentro de una de las partes a ordenar. Puede parecer una pequeña optimización sin importancia, pero no lo es.
Si dejamos el pivote dentro de una de las partes a ordenar, y además ocurre que esa parte ocupa todo el array a ordenar (quedando la otra parte vacía), entonces se provoca una recursividad infinita.
Hay varios detalles que modifican el impacto de este problema, como la forma de elegir el pivote o si los valores iguales al pivote se reparten o se dejan en un lado. No obstante, la única manera de resolver este problema al cien por cien es excluir al pivote de ambas partes, dejándolo situado en su posición definitiva. Así se garantiza que cada llamada recursiva reduzca el tamaño del problema en al menos un elemento.
2. Usar siempre el primer elemento como pivote (o siempre el último)
Esto no tendría importancia si todas las permutaciones posibles se dieran con la misma probabilidad. Pero la realidad es diferente. Los casos especiales de «datos ya ordenados» (al derecho o al revés) o «datos casi ordenados» son bastante frecuentes en comparación con otras permutaciones. Y en esos casos, el primer elemento y el último son los peores candidatos para la elección del pivote.
Si usamos siempre el primer elemento (o siempre el último) como pivote, quicksort degenera en su peor comportamiento con datos ya ordenados, tanto si están en orden ascendente como si están en orden descendente.
Este problema se suele resolver de dos maneras diferentes:
Usar como pivote la mediana tres elementos: el primero, el último y el central
Usar como pivote el elemento de una posición escogida al azar
Ambos métodos reducen la probabilidad de que se dé el peor caso, pero no la eliminan completamente.
3. Creer que usar como pivote la mediana de 3 o un elemento al azar evita completamente el peor caso
El peor caso aún puede darse. Puede que sea muy improbable, pero sigue siendo posible. Este es el tipo de problema que no se detecta en las pruebas y que se puede manifestar más tarde, cuando las consecuencias son más graves.
No es sólo una cuestión de probabilidad. Un atacante que pueda introducir datos en nuestro sistema podría disponerlos justamente de forma que provoquen el peor comportamiento de quicksort.
Debemos tener en cuenta que el peor caso puede darse. Conviene que las pruebas lo ejerciten para evaluar las consecuencias en cuanto al tiempo requerido y la memoria adicional utilizada.
4. Hacer dos llamadas recursivas en vez de utilizar recursividad de cola
La recursividad de cola se implementa sustituyendo una de las llamadas recursivas por un bucle. De esta forma se reduce ligeramente el tiempo de ejecución.
Parece una simple optimización, pero en realidad es imprescindible para que la memoria adicional requerida sea O(log N) incluso en el peor caso. Aún así, no basta simplemente con usar recursividad de cola de cualquier manera. A continuación explico por qué.
5. Utilizar recursividad de cola, pero siempre en el mismo lado
Si no se usa recursividad de cola, o si se usa siempre en el mismo lado, el espacio de memoria adicional requerido en el peor caso será del orden de O(N), es decir, proporcional al número de elementos a ordenar. Eso puede provocar un desbordamiento de pila.
La razón es que en el peor caso se llegarán a anidar hasta O(N) llamadas recursivas y cada una de ellas ocupa algo de memoria.
Lá única manera de resolver esto pasa por usar recursividad de cola en la llamada correspondiente a la parte más grande. Así se asegura que sólo se anidarán O(log N) llamadas recursivas.
6. Creer que la recursividad de cola evita todos los problemas
La recursividad de cola, usada correctamente, resuelve el problema del espacio. Pero siguen existiendo otros problemas. El tiempo del peor caso sigue siendo
O(N2)
. Como ya he comentado, la forma de elegir el pivote puede ayudar a que este caso sea poco probable en la práctica. Si «poco probable» no es suficiente, entonces hay que recurrir a algún otro algoritmo que tarde O(N log N) también en el peor caso, aunque en el caso medio tarde varias veces más que quicksort.
Pero aquí no acaba la cosa. Queda un sutil detalle que puede convertir ese «poco probable» en «vergonzosamente frecuente»:
7. Dejar todos los elementos iguales al pivote en un lado
Al hacer la partición, ¿qué hay que hacer con los elementos que resultan ser iguales que el pivote? A simple vista parece un detalle sin importancia. Podemos dejarlos en cualquiera de los dos lados. El algoritmo ordenará correctamente. Además, no habrá muchos elementos iguales al pivote, ¿verdad? ¡Oh! Un momento…. ¡A lo mejor hay muchos!
Cuando hablamos de algoritmos de ordenación tendemos a pensar en valores distintos entre sí, pero en la vida real ocurre con bastante frecuencia que muchos elementos tienen un mismo valor. Supongamos que hay que ordenar los datos de 47 millones de habitantes según su estado civil (soltero/a, casado/a…). Tras un par de niveles de recursividad es posible que todos o casi todos los elementos del fragmento a ordenar sean iguales entre sí en lo que respecta al estado civil. ¿Qué pasará entonces?
La probabilidad de que el pivote elegido tenga ese valor es altísima, así que habrá muchos elementos iguales al pivote. Si los ponemos todos al mismo lado haremos una partición ineficiente. ¡La peor de todas las posibles! Quicksort exhibirá su peor comportamiento en un caso que, en principio, parecía absurdamente fácil. Este es seguramente el mayor problema porque los libros de algoritmos no hacen suficiente hincapié en él, si es que lo mencionan.
La solución es repartir equitativamente los elementos iguales al pivote entre las dos partes, aunque a primera vista parezca que movemos los datos innecesariamente. Podéis encontrar una implementación aquí.
En cualquier caso insisto: la mejor opción es casi siempre usar el método de ordenación que proporciona el propio lenguaje de programación en su biblioteca de funciones ;-)
En C++, por ejemplo se puede elegir entre std::sort y std::stable_sort.
En el terreno de la ordenación con poca memoria adicional han destacado varios favoritos a lo largo de la historia: Shellsort (1959), quicksort (1960), heapsort (1964) y más recientemente introsort (1997), que es un híbrido de quicksort, heapsort y la ordenación por inserción.
Mergesort (1945) dominó muchos años en el terreno de la ordenación estable. Su sustituto parece ser Timsort (2002). Se trata también de un híbrido, en este caso de mergesort, la ordenación por inserción y algún truco más.
Hablaré de los pocos casos en los que sí tendría sentido (en mi opinión) usar un algoritmo de ordenación programado a medida. Pero será más adelante ;-)
ProjectEuler.net es un invento magnífico que conocí hace un par de años. Alberga una interesantísima colección de problemas de programación.
Los primeros problemas son relativamente sencillos. Después la dificultad aumenta según se avanza.
Todos los problemas están diseñados para que se puedan resolver con menos de un minuto de procesamiento en un ordenador normal. Muchos de ellos requieren sólo un puñado de microsegundos. Cualquier lenguaje como C o Java con enteros de 64 bits debería bastar. Mucha gente usa otros lenguajes.
En principio los usuarios nuevos sólo tienen acceso a los enunciados de los problemas.
Por cada problema existe un foro en el que los usuarios anteriores han ido compartiendo sus soluciones. Para muchos problemas también hay un resumen en PDF que explica las posibles soluciones.
Pero los usuarios sólo pueden acceder al foro y al PDF de un problema tras haberlo resuelto y haber introducido la respuesta correcta en la página web.
A simple vista podría parecer que esto no tiene mucho sentido. ¿Qué interés puede tener para un usuario que ya ha encontrado la solución? ¡Pues mucho! A menudo hay varias maneras de resolver un problema y no son todas igual de eficientes. El foro y el PDF de un problema contienen pistas vitales para poder encarar los problemas posteriores.
De los cientos de problemas que hay en Project Euler, yo he resuelto 81 hasta la fecha. Gracias a ello he aprendido mucho acerca de combinatoria y programación dinámica, entre otras cosas. Respecto a esto último, por cierto, tengo planeado escribir algún día en este blog.
Aparte de haber resuelto unos cuantos problemas, tengo el orgullo de haber aportado mi granito de arena a Project Euler: me presté voluntario para la confección de los PDF de los problemas 31 y 53.
Por desgracia, Project Euler lleva un tiempo funcionando a medio gas. Los administradores descubrieron que alguien se había colado en su base de datos y cerraron la web completamente. Después la volvieron a abrir pero con «funcionalidad reducida». Es decir, que se puede acceder a los enunciados de los problemas y se puede comprobar si una solución es correcta, pero no hay foros ni resúmenes en PDF.
Replicar aquí los enunciados o dar pistas sobre las soluciones iría en contra de la filosofía de Project Euler, así que me limitaré a enlazar los enunciados…
«¡Naturalmente! Lo hago todos los días» — pensarás.
No, no, no. Ya me imagino que sabes atarte los cordones. Lo que pregunto es si sabes cómo lo haces. ¿Sabrías describirlo paso a paso, con palabras o con dibujos? Eso ya es otra historia… No vale ensayar. No puedes ni mirar tus zapatos. ¿Cómo mueves cada dedo en cada momento?
Si sabes describir cómo te atas los cordones, probablemente es porque has tenido que enseñar a alguien cómo hacerlo.
Con la programación ocurre algo parecido. Tenemos que enseñarle al ordenador cómo hacer tareas que nosotros sabemos realizar. Pero tenemos que describirlas con todo detalle, en un lenguaje muy limitado. El ordenador no sobreentiende nada. A menudo nos encontramos reflexionando duramente para separar los pasos elementales de un proceso que nosotros realizamos de una forma automática, casi inconsciente.
Ahí reside una de las dificultades de la programación. La otra dificultad es que, siguiendo con la analogía, necesitaremos que el ordenador haga todos los nudos marineros conocidos… y alguno más.
Blog sobre programación y lo que se me vaya ocurriendo